ایندکس کردن متن: اولین قدم در RAG

در دومین پست از سری آموزشهای “RAG از صفر”، به موضوع مهم ایندکس کردن یا فهرست سازی پرداختیم. اگر پست اول را خوانده باشید، با اجزای اصلی RAG آشنا شدهاید: ایندکس، بازیابی و تولید. اکنون، قصد داریم بهصورت عمیقتر به ایندکس بپردازیم و نحوه عملکرد آن را بررسی کنیم.
ایندکس چیست و چرا اهمیت دارد؟
وقتی ما از ایندکس صحبت میکنیم، در واقع به دنبال بارگذاری مجموعهای از سندها یا مدارک داریم. این اسناد میتوانند شامل مقالهها، کتابها، یا هر نوع اطلاعات دیگری باشند که برای ما ارزشمندند.
در ایندکس، ما باید این اسناد را بارگذاری کنیم و در بازیاب یا retrieval قرار دهیم. این بازیاب به نوعی مانند یک کتابخانه دیجیتال عمل میکند. شما میتوانید به سادگی یک سوال از آن بپرسید و بازیاب تمام تلاش خود را میکند تا مدارکی را که به سوال شما مرتبط هستند پیدا کند و در اختیار شما قرار دهد.
حالا بیایید نگاهی به چگونگی عملکرد ایندکس کردن بیندازیم. ابتدا، تمام اسناد خارجی را بارگذاری میکنیم. بعد از این مرحله، آنها را در یک ساختار خاص سازماندهی میکنیم تا بازیاب بتواند به راحتی و به سرعت آنها را پیدا کند. این کار مشابه این است که در یک کتابخانه، کتابها را بر اساس موضوع، نویسنده یا تاریخ انتشار مرتب کنیم. این مرتبسازی و سازماندهی کمک میکند تا بتوانیم سریعتر اطلاعات مورد نظر خود را پیدا کنیم.
برای این کار، اسناد بایستی به نمایشهای عددی یا وکتور تبدیل شوند. این تبدیل به دلیل سهولت مقایسه وکتورها در برابر متنهای نامنظم و پیچیده صورت میگیرد.
روشهای ایندکس کردن
روشهای مختلفی به مرور زمان توسعه یافتهاند که امکان ایندکس کردن اسناد متنی به نمایههای عددی را فراهم میآورند.
یکی از رویکردهای بسیار رایج، استفاده از روشهای آماری است. شرکتهایی مانند گوگل از شیوههایی استفاده کردهاند که در آنها به تکرار واژهها در یک سند توجه میشود. در این روش، یک بردار خلوت (sparse vectors) ایجاد میشود. تصور کنید که این بردار شامل موقعیتهایی است که به واژههای مختلف یک دیکشنری بزرگ مربوط میشوند. هر مقدار در این بردار نشاندهنده تعداد تکرار یک واژه خاص در سند است.
به عبارت سادهتر، برای هر واژه در دیکشنری، ما یک عدد داریم که نشاندهنده تعداد دفعاتی است که آن واژه در متن آمده است. حالا، از آنجایی که واژههای زیادی وجود دارند و معمولاً هر سند تنها تعدادی از آنها را شامل میشود، خیلی از مفادیر در این بردار خالی میمانند و به همین دلیل به آن خلوت میگویند.
اخیراً روشهای جدیدتری به نام embedding توسعه یافته است. در این روش ما یک سند را به یک بردار فشرده و با طول ثابت تبدیل میکنیم. این نمایهها به نوعی دیگر، از روشهای آماری هستند اما با تکنیکهای یادگیری ماشین بهبود یافتهاند.
ایده اصلی در اینجا این است که هنگامی که از مدلی برای ایجاد این embeddingها استفاده می کنیم، معمولاً سند را به بخشهای کوچکتری تقسیم میکنیم، چرا که این مدلها معمولاً دارای محدودیتهای اندازهای هستند. به عنوان مثال، میتوانند فقط تعداد محدودی از کلمات (حدود 512 تا 8000 کلمه) را هر دفعه پردازش کنند.
اینکه embeddingها میتوانند در جستوجو و تحلیل دادهها مفید باشند به این دلیل است که میتوانند اطلاعات مفیدی را در یک فرمت فشرده و قابلجستوجو ذخیره کنند. به طور کلی، embeddingها به ما این امکان را میدهند که به جای جستوجو در میان کلمات بهصورت مجزا، به جستوجو در یک فضای عددی با ویژگیهای مرتبط بپردازیم.
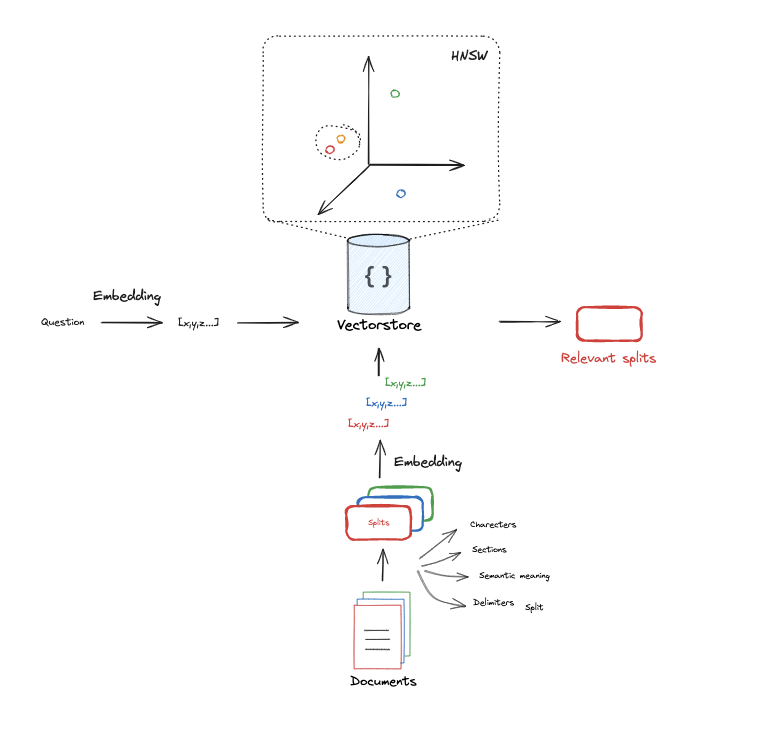
چطور ایندکس کردن انجام میشود؟
برای ایندکس کردن، معمولاً سندها به قسمتهای کوچکتری تقسیم میشوند، زیرا مدلهای امبدینگ تنها میتوانند تعداد محدودی توکن (معمولاً بین ۵۱۲ تا ۸۰۰۰) را پردازش کنند. هر قسمت سند به یک وکتور فشرده تبدیل شده و سپس ایندکس میشود. این وکتورها نمایانگر معنا و مفهوم سند هستند و با استفاده از مقایسههای عددی میتوانند مدارک مرتبط با سوالها را پیدا کنند.
کاربرد عملی و نمایش کدها
متن زیر را به عنوان مدرکی که میخواهیم از آن اطلاعات را استخراج کنیم در نظر بگیرید.
# Documents
question = "What kinds of pets do I like?"
document = "My favorite pet is a cat."
کد زیر یک تابع ساده برای محاسبه تعداد توکنها (tokens) در یک رشته متنی با استفاده از کتابخانه tiktoken است. شمارش توکنها با در نظر گرفتن اینکه هر توکن معادل 4 کاراکتر است
import tiktoken
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
num_tokens_from_string(question, "cl100k_base")
کد زیر برای تولید بردارهای embeddings از متن با استفاده از کتابخانه langchain_openai است:
from langchain_openai import OpenAIEmbeddings
embd = OpenAIEmbeddings()
query_result = embd.embed_query(question)
document_result = embd.embed_query(document)
len(query_result)
کد زیر برای محاسبه شباهت کسینوس (Cosine Similarity) بین دو بردار استفاده میشود. شباهت کسینوس یکی از روشهای متداول برای اندازهگیری میزان شباهت بین دو بردار است.
import numpy as np
def cosine_similarity(vec1, vec2):
dot_product = np.dot(vec1, vec2)
norm_vec1 = np.linalg.norm(vec1)
norm_vec2 = np.linalg.norm(vec2)
return dot_product / (norm_vec1 * norm_vec2)
similarity = cosine_similarity(query_result, document_result)
print("Cosine Similarity:", similarity)
به منظور استخراج محتوای یک پست از وبسایت lilianweng.github.io از کد زیر استفاده میکنیم:
#### INDEXING ####
# Load blog
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
blog_docs = loader.load()
در این کد با استفاده از کتابخانه Langchain یک متن را به بخشهای کوچک تقسیم میکنیم:
# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=300,
chunk_overlap=50)
# Make splits
splits = text_splitter.split_documents(blog_docs)
با استفاده از کتابخانههای LangChain و Chroma و متون تکه شده یک vectorstore از متون ایجاد مکنیم:
# Index
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits,
embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
هدف کلی این کد ایجاد یک سیستم جستجوی برداری است که قادر است به صورت مؤثر در میان متون جستجو کند و با استفاده از embeddings تولید شده توسط مدلهای OpenAI، نتایج جستجو را بهبود بخشد.