تنظیمات LLM
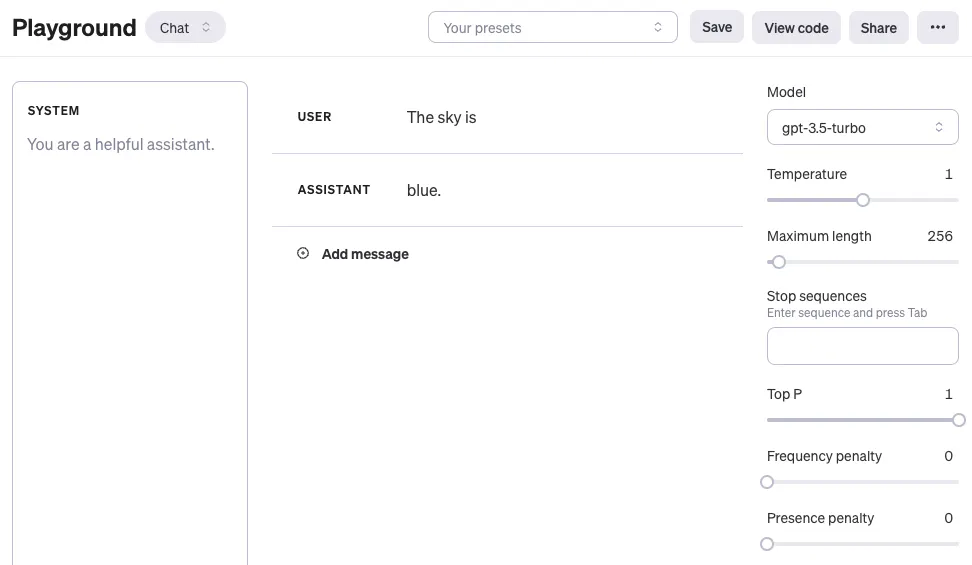
معمولاً از طریق API با مدل زبانی بزرگ (LLM) ارتباط برقرار میکنن. میتونی چندتا پارامتر رو تنظیم کنی تا نتایج مختلفی برای پیامهات بگیری. دستکاری این تنظیمات مهمه چون به بهبود دقت و کیفیت پاسخها کمک میکنه و یکم تجربه لازم داره تا بفهمی کدوم تنظیمات برای کارت بهتره. در ادامه تنظیمات معمولی که موقع استفاده از LLMهای مختلف باهاشون روبرو میشین رو آوردم. برای آزمایش این موارد میتونین به بخش playground سایت openai از این آدرس برین. اگه مشکلی برای این کار داشتین به راهنمای ساخت حساب کاربری در سایت OpenAi مراجعه کنید:
دمای مدل یا Temperature
به طور خلاصه، هرچی دما پایینتر باشه، نتایج قابل پیشبینیتر هستن چون همیشه محتملترین کلمه بعدی انتخاب میشه. بالا بردن دما میتونه باعث بشه نتایج تصادفیتر بشن، که این به تنوع و خلاقیت بیشتر کمک میکنه. در واقع با این کار وزن کلمات احتمالی دیگه رو بیشتر میکنی. یا مثلاً اگه بخوای از مدل برای سوال و جوابهای مبتنی بر واقعیت استفاده کنی، بهتره دما رو پایین نگه داری تا پاسخها دقیقتر و مختصرتر باشن. برای کارهای خلاقانه مثل شعر، میتونی دما رو بالاتر ببری تا نتایج متنوعتر و خلاقانهتری بگیری.
Top P
یک روش دیگه انتخاب کلمات که مشابه با دما است و بهش میگن نمونهگیری هستهای nucleus sampling. با این روش میتونی کنترل کنی که مدل چقدر قابل پیشبینی باشه. اگه دنبال جوابهای دقیق و واقعبینانهای، این مقدار رو پایین نگه دار. اگه دنبال پاسخهای متنوعتری هستی، مقدارش رو بالا ببر. وقتی از Top P استفاده میکنی، یعنی فقط کلماتی که مجموع احتمالشان به top_p میرسه برای پاسخها در نظر گرفته میشه. پس مقدار پایین top_p جوابهای مطمئنتری میده. در مقابل، مقدار بالای top_p به مدل اجازه میده کلمات بیشتری رو، حتی اونایی که کمتر محتمل هستن، بررسی کنه که منجر به خروجیهای متنوعتری میشه.
توصیه عمومی اینه که یا دما رو تغییر بدی یا Top P رو، ولی نه هر دو رو همزمان.
Max Length
تعداد کلماتی که مدل تولید میکنه رو میتونی با تنظیم حداکثر طول کنترل کنی. تعیین حداکثر طول بهت کمک میکنه که از پاسخهای طولانی یا نامربوط جلوگیری کنی و هزینهها رو هم کنترل کنی.
Stop Sequences
یک stop sequence رشتهایه که جلوی مدل رو از تولید کلمات بیشتر میگیره. تعیین stop sequence یکی دیگه از راههای کنترل طول و ساختار پاسخ مدل هست. مثلاً میتونی به مدل بگی لیستی که تولید میکنه بیشتر از 10 آیتم نداشته باشه، با اضافه کردن “11” به عنوان stop sequence.
frequency penalty
جریمه تکرار (frequency penalty) یه جریمه به کلمه بعدی اعمال میکنه که نسبت به تعداد دفعاتی که اون کلمه قبلاً توی پاسخ و پیام ظاهر شده، متناسبه. هرچی جریمه تکرار بالاتر باشه، احتمال دوباره ظاهر شدن یه کلمه کمتر میشه. این تنظیم با دادن جریمه بیشتر به کلمات تکراری، باعث میشه که مدل کمتر کلمات رو تکرار کنه.
Presence Penalty
جریمه حضور (presence penalty) هم برای کلمات تکراری جریمه اعمال میکنه، اما برخلاف جریمه تکرار، این جریمه برای همه کلمات تکراری یکسانه. یعنی کلمهای که دو بار تکرار شده و کلمهای که ده بار تکرار شده، به یک اندازه جریمه میشن. این تنظیم کمک میکنه که مدل جملات و عبارات رو زیاد تکرار نکنه. اگه میخوای مدل متنهای متنوع یا خلاقانهتری تولید کنه، میتونی از جریمه حضور بالاتری استفاده کنی. یا اگه نیاز داری مدل بیشتر متمرکز بمونه، جریمه حضور کمتری به کار ببر.
مشابه تنظیمات دما و top_p، توصیه عمومی اینه که جریمه تکرار یا جریمه حضور رو تغییر بدی، ولی نه هر دو رو با هم.
قبل از شروع با چند مثال ساده، این رو هم در نظر داشته باش که نتایجت ممکنه بسته به نسخه LLM که استفاده میکنی، متفاوت باشه.