درخت افکار (Tree of Thoughts یا ToT)
درخت افکار (Tree of Thoughts یا ToT) مناسب کارهای پیچیدهایه که نیاز به کاوش یا تفکر استراتژیک دارند و روشهای ساده و معمولی جوابگو نیستند. یائو و همکارانش (۲۰۲۳) و لانگ (۲۰۲۳) یک چارچوب به نام درخت افکار را پیشنهاد کردهاند که به نوعی برای ارائه افکار میباشد و کاوش در افکار را تشویق میکند؛ افکاری که میتوانند به عنوان مراحل میانی برای حل مسائل مختلف با مدلهای زبانی به کار بروند.
روش ToT (درخت افکار) یه درخت درست میکنه که تو هر شاخهاش یه سری افکار منظم وجود دارن. این افکار در واقع جملاتی هستن که به صورت مرحلهای به حل یک مسأله کمک میکنن. این روش به مدلهای زبانی (LM) کمک میکنه که بتونن خودشون رو ارزیابی کنن و ببینن تا الان چقدر به حل مسأله نزدیک شدن. توانایی مدل در تولید و ارزیابی افکار با استفاده از الگوریتمهای جستجو (مثل سطحی و عمقی) ترکیب میشه تا بشه سیستماتیک فکرها رو بررسی کرد و جلو و عقب رفت تو مسیر.
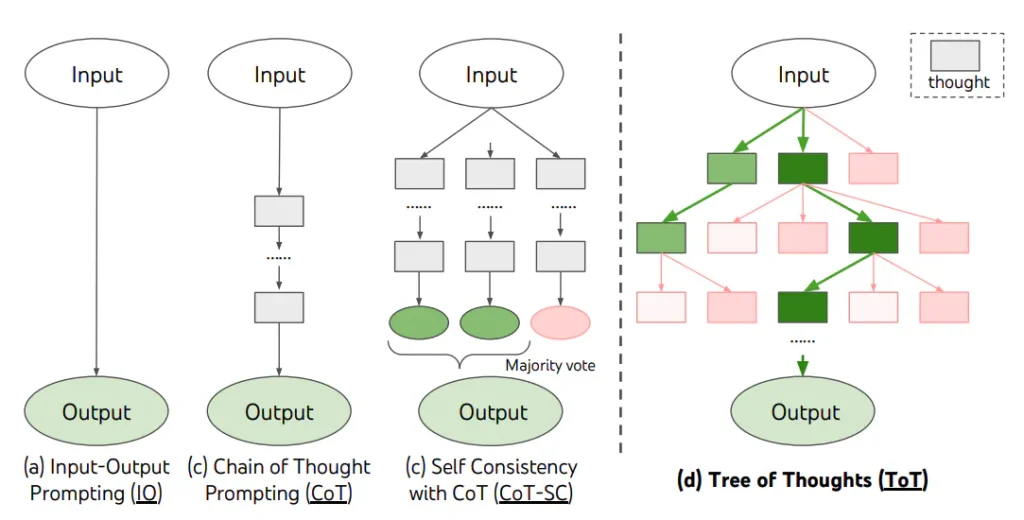
وقتی از ToT استفاده میکنیم، برای کارهای مختلف باید تعداد کاندیداها و تعداد افکار یا مراحل رو مشخص کنیم. مثلاً، همونطور که تو مقاله توضیح داده شده، بازی ۲۴ به عنوان یه کار ریاضی در نظر گرفته شده که نیاز داره افکار به ۳ مرحله تقسیم بشه و هر مرحله شامل یه معادلهی واسطهای باشه. تو هر مرحله، ۵ کاندیدای برتر نگه داشته میشن.
برای انجام جستجوی سطح به سطح (BFS) در بازی 24 (24 یک بازی عددی است که در آن باید با استفاده از چهار عدد داده شده و عملیات ریاضی (جمع، تفریق، ضرب، تقسیم) به عدد ۲۴ برسید)، مدل زبان (LM) ازش خواسته میشه که هر ایدهای که بهش میده رو به عنوان “مطمئن/شاید/غیرممکن” از نظر رسیدن به عدد 24 ارزیابی کنه. طبق گفتههای نویسندگان، “هدف اینه که راهحلهای جزئی درست که میشه توی چند مرحله بعدی بهشون رسید رو ترویج بدیم و راهحلهای جزئی غیرممکن رو با توجه به «خیلی بزرگ/کوچیک بودن» از نظر عقل سلیم حذف کنیم و بقیه رو به عنوان «شاید» نگه داریم.” برای هر ایده سه بار مقدارگیری صورت میگیره. روند کار در تصویر زیر نشان داده شده:

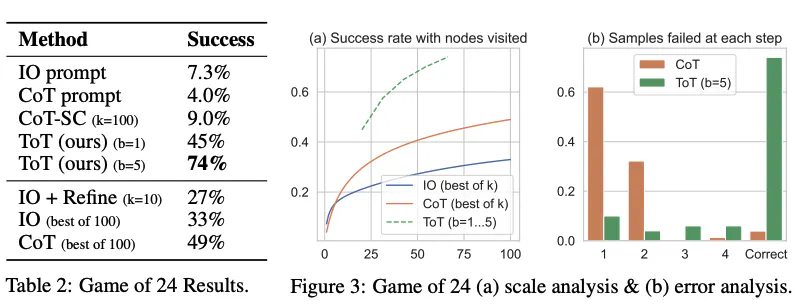
طبق نتایج گزارششده در شکل زیر، ToT عملکرد بهتری نسبت به روشهای پیشنهادی دیگه داره:
ایدههای اصلی مقالات Yao و همکاران (۲۰۲۳) و Long (۲۰۲۳) خیلی شبیه هم هستن. هر دوی اینا میخوان توانایی حل مسائل پیچیده ماشینهای زبان بزرگ (LLM) رو با استفاده از یه گفتگوی چند مرحلهای تقویت کنن. اما یکی از فرقهای اصلیشون اینه که Yao و همکاران از روشهای جستجوی درخت مثل DFS، BFS و Beam search استفاده میکنن، در حالی که توی مقاله Long (۲۰۲۳)، راهبرد جستجوی درخت با کمک یه “کنترلر ToT” که از طریق یادگیری تقویتی آموزش دیده، کنترل میشه.
DFS، BFS و beam search راهکارهای عمومی برای جستوجوی راه حل هستن و به مسائل خاص تناسب ندارن. در مقایسه، یک کنترلکننده ToT که با یادگیری تقویتی آموزش دیده میتونه از دادههای جدید یا از بازی خود با خودش یاد بگیره (مثل بازی AlphaGo) و در نتیجه سیستم ToT مبتنی بر یادگیری تقویتی میتونه به تکامل و یادگیری دانش جدید ادامه بده، حتی زمانی که مدل زبان ثابت باشه.
هالبِرت (۲۰۲۳) (در یک تب جدید باز میشه) یه روش به اسم Tree-of-Thought Prompting رو پیشنهاد کرده. این روش از ایده اصلی چارچوب ToT به عنوان یک تکنیک ساده استفاده میکنه که از مدلهای زبانی بزرگ (LLM) میخواد که افکار میانی خودشون رو تو یک پیام ارزیابی کنن. یه نمونه از پیام ToT اینجوریه:
فرض کنید سه کارشناس مختلف به این سؤال پاسخ میدهند. هر کدام از کارشناسان یک مرحله از تفکر خود را نوشته، سپس آن را با گروه به اشتراک میگذارد. پس از آن، هر سه کارشناس به مرحله بعدی میروند و این روند ادامه پیدا میکند. اگر در هر مرحله هر کدام از کارشناسان متوجه شود که اشتباه کرده، از جمع خارج میشود. سؤال این است…
Sun (2023) انگیزه درخت افکار را با آزمایشهایی در مقیاس بزرگ بنچمارک کرد و PanelGPT، ایدهای پرامپتنویسی با پنل بحث بین LLMها را معرفی کرد.