راهنمای جامع استفاده از RAG در مدلهای زبانی بزرگ (LLMs) در کتابخانه LangChain
در دنیای هوش مصنوعی و پردازش زبان طبیعی، مدلهای زبانی بزرگ (LLM) تواناییهای بینظیری در تولید متن دارند. اما یک محدودیت مهم در این مدلها وجود دارد: آنها نمیتوانند به دادههای خصوصی یا دادههای جدید که بعد از پیشآموزش در دسترس قرار گرفتهاند، دسترسی داشته باشند. این یعنی حتی با وجود حجم عظیم دادههایی که مدلها با آن آموزش دیدهاند، باز هم نمیتوانند به طور کامل به اطلاعات خاصی که شما نیاز دارید پاسخ دهند.
برای حل این چالش، روشی به نام “تولید با تقویت اطلاعات ” “Retrieval-Augmented Generation” یا همان RAG معرفی شده است. در این روش، مدلهای زبانی با دادههای خارجی که بهطور خاص به نیازهای شما مرتبط هستند، تقویت میشوند. این کار به مدل اجازه میدهد تا از اطلاعات بهروزتر و خصوصیتر برای پاسخگویی دقیقتر استفاده کند.

چرا RAG اهمیت دارد؟
یکی از دلایل اصلی استفاده از RAG این است که حتی بزرگترین مدلهای زبانی هم نمیتوانند همهی اطلاعات مورد نیاز شما را شامل شوند. بهویژه دادههای اختصاصی شما یا اطلاعات جدید که ممکن است بعد از دورهی آموزش مدل به وجود آمده باشند. هرچند مدلهای زبانی روز به روز پنجرههای متنی بزرگتری دارند (از هزاران توکن به دهها یا صدها صفحه)، اما همچنان نمیتوانند همه چیز را در بر بگیرند. بنابراین، افزودن اطلاعات از منابع خارجی به یک مدل زبانی میتواند یک قابلیت کلیدی باشد.
RAG، مانند یک سیستمعامل جدید، به مدل زبانی شما این امکان را میدهد تا به دادههای خارجی دسترسی داشته باشد و این دسترسی به دادهها نقش بسیار مهمی در توسعه سیستمهای هوش مصنوعی دارد.
فرآیند اجرای RAG چگونه است؟
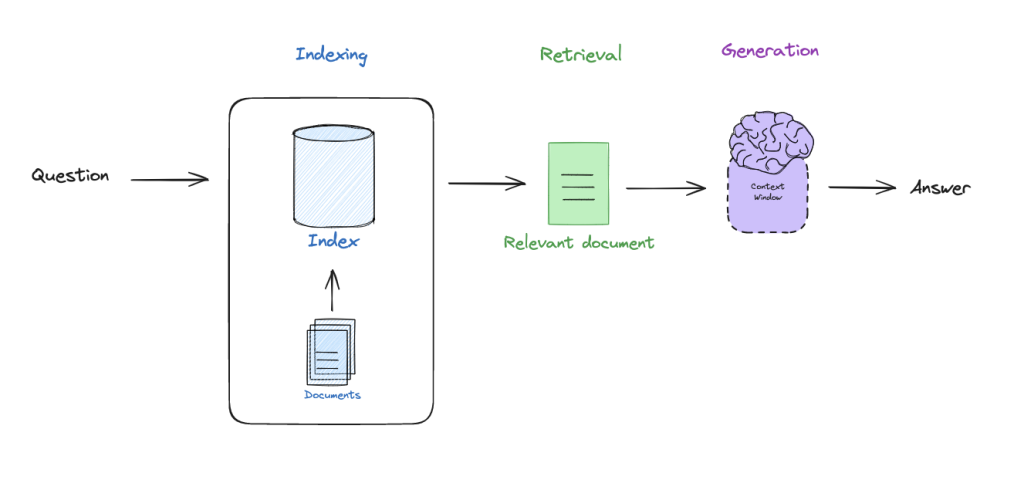
روش RAG معمولاً شامل سه مرحلهی کلیدی است:
- فهرستبرداری (Indexing): ابتدا اسناد خارجی را ایندکس میکنیم تا در صورت نیاز، به سرعت بتوانیم به آنها دسترسی پیدا کنیم. به عنوان مثال، هنگامی که سوالی مطرح میشود، اسناد مرتبط با آن پرسش بازیابی میشوند.
- بازیابی (Retrieval): مدارک ایندکس شده را بر اساس سوال بازیابی میکنیم.
- تولید (Generation): در این مرحله، مدل زبانی با استفاده از مدارک بازیابی شده، پاسخ نهایی را تولید میکند.
نگاهی عمیقتر به RAG
با نگاهی دقیقتر به این سه مرحله، میبینیم که RAG شامل جزئیات و ترفندهای جالبی است. در آینده، قصد داریم در پستهای کوتاه، به بررسی این مراحل و تکنیکهای پیشرفتهتر بپردازیم.
برای شروع، میخواهیم یک راهنمای کدنویسی ارائه دهیم تا این مطالب را به صورت تعاملی درک کنید. در مخزن عمومی موجود، یک نوتبوک باز کردهایم که در آن بستههای لازم نصب شده و برخی متغیرهای محیطی برای اجرای RAG آماده شدهاند. این نوتبوک برای مشاهده فرایندهای RAG بسیار مفید است.
! pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain
برای گرفتن Api لنگچین از این آدرس استفاده کنید
import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = 'https://api.smith.langchain.com'
os.environ['LANGCHAIN_API_KEY'] = <your-api-key>
برای گرفتن OpenAi Api از این آدرس استفاده کنید
os.environ['OPENAI_API_KEY'] = <your-api-key>
import bs4
from langchain import hub
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
شروع سریع با RAG
در اینجا، مثالی از نحوه شروع سریع با RAG آوردهایم. ابتدا، اسناد را بارگذاری میکنیم.برای مثال، یک پست وبلاگ:
# Load Documents
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
سپس اسناد را به تکههای کوچکتر تقسیم میکنیم (هر تکه حدود هزار کاراکتر).
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
این تکهها در یک فضای ذخیرهسازی وکتور (مثل Chroma) فهرستبندی میشوند.
vectorstore = Chroma.from_documents(documents=splits,
embedding=OpenAIEmbeddings())
سپس از یک بازیاب (retriever) استفاده میکنیم تا اسناد مرتبط را بیابیم.
retriever = vectorstore.as_retriever()
در نهایت، مدل زبانی (LLM) اسناد بازیابی شده و سوال را پردازش کرده و پاسخ را تولید میکند.
# Prompt Template
prompt = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# Question
rag_chain.invoke("What is Task Decomposition?")
در طول این فرایند، از OpenAI استفاده کردهایم و دیتابیس وکتور به صورت لوکال اجرا میشود. در نهایت، میتوانید خروجی را در ابزار LSmith مشاهده کنید و بررسی کنید که چطور مدل با استفاده از اطلاعات بازیابی شده، به سوال شما پاسخ داده است.